
Guardrails First: Why STM’s Vision Must Anchor Responsible AI in Research


Opinion | March 2026
The International Association of Scientific, Technical and Medical Publishers (STM) has proposed one of the most comprehensive frameworks yet for governing generative AI in scholarly communication. At a time when AI tools are rapidly reshaping how knowledge is accessed, interpreted, and produced, STM’s intervention carries weight not only because of its timing, but because of its authority. Representing publishers responsible for a majority of the world’s scholarly output, STM is not merely participating in the conversation; it is helping define its terms through its Generative AI Guidelines (STM Association, 2023).
Trust is Built on Systems, Not Outputs
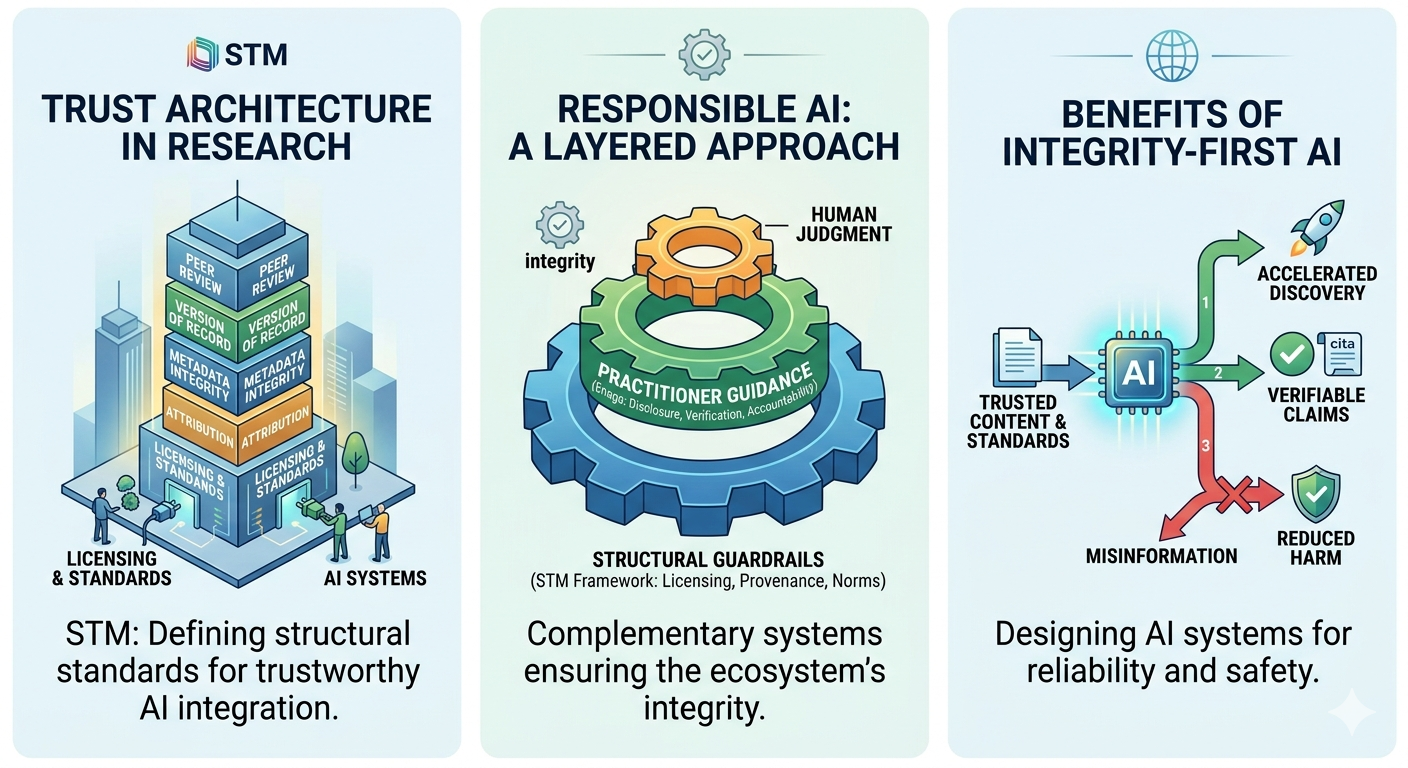
At the heart of STM’s brief is a simple but powerful assertion: Generative AI must operate within the same standards that underpin trusted research. Peer review, the Version of Record, formal correction mechanisms, and rigorous attribution are not optional features of scholarly communication; they are its foundation. As stated in the white paper on AI in scholarly communications, any system that engages with research content without respecting these elements risks weakening the very structure on which it depends (STM Association, 2021).
This systems-level perspective is STM’s contribution is most significant. It recognizes that trust in research is not an emergent property of technology, but the result of carefully maintained processes. By emphasizing licensing, metadata integrity, differentiation of content types, and transparency across training and inference layers, STM addresses the architecture of trust rather than just its outcomes.
The risks of ignoring this architecture are not merely hypothetical. AI systems that fail to distinguish between peer-reviewed research and preliminary findings can blur critical boundaries. Missing or incorrect citations can make claims unverifiable. In high-stakes domains such as medicine, these failures can extend beyond academic consequences into real-world harm. STM’s insistence on embedding scholarly norms into AI systems is therefore not conservative; it is necessary for maintaining the integrity of the scholarly record (STM Association, 2026).
Where Systems Meet Practice
STM’s framework implicitly recognizes that systems alone are not enough. The reliability of AI-generated outputs also depends on how researchers use these tools in practice. This is where practice-oriented efforts, such as Enago’s Responsible AI guidance, enter the picture. While STM defines what trustworthy AI systems should look like, Enago addresses how those systems are used on the ground.
Enago’s approach centers on researcher behavior: transparent disclosure of AI use, careful verification of outputs, and clear human accountability for any generated content. These principles are particularly relevant as AI becomes embedded in writing, editing, and literature review workflows. They reinforce an important reality: even the most well-designed system cannot replace human judgment, a sentiment emphasized in the Enago ethical AI guidelines.
However, this layer of responsibility operates within limits. A researcher can verify claims and disclose AI assistance, but cannot easily compensate for structural gaps such as missing attribution, unclear source hierarchy, or the blending of validated and non-validated content. In this sense, Enago’s guidance is enabling rather than foundational. It strengthens responsible use, but depends on the kind of infrastructure that STM is seeking to establish.
This distinction matters because it clarifies where responsibility ultimately lies. Responsible behavior is essential, but it cannot substitute for responsible design. Without system-level safeguards, individual diligence becomes inconsistent and difficult to scale.
The Tension Between Openness and Control
STM’s framework also raises a more complex question about the balance between protection and access. Its emphasis on copyright and licensing reflects legitimate concerns about intellectual property and the sustainability of scholarly publishing. Yet it also reinforces a system in which high-quality research is often restricted. If generative AI tools are required to prioritize licensed, publisher-controlled content without parallel efforts to expand access, the result may be a more controlled, rather than more open, knowledge ecosystem.
Still, this tension does not diminish STM’s central contribution. If anything, it underscores the importance of having authoritative bodies engage directly with AI governance. The alternative, a fragmented landscape shaped primarily by technology companies or informal norms, would likely produce far less accountability.
What STM offers is a foundation. It defines the non-negotiables of trust in scholarly communication and insists that AI systems must align with them. Around this foundation, complementary efforts like Enago’s play a supporting role, reinforcing responsible practices at the level of individual researchers and day-to-day workflows.
Why Guardrails Matter
The future of generative AI in research will not be determined by a single framework. It will emerge from the interaction between systems, institutions, and individuals. But not all layers carry equal weight. Without strong structural standards, the entire system becomes fragile.
STM understands this. Its consultation document is not just a call for feedback; it is an attempt to ensure that as AI accelerates discovery, it does so without compromising the principles that make discovery meaningful. Generative AI may change how research is done; it should not change what makes research trustworthy.
Generative AI may change how research is conducted; it should not change what makes research trustworthy.
Bibliography
Enago. (2023). Author Guidelines for the Use of Generative AI Tools in Scholarly Publishing. Enago Academy. www.enago.com
Enago. (2026). The Author Guide to Responsible AI Movement. www.enago.com
STM Association. (2021). AI in Scholarly Communications: A White Paper. International Association of Scientific, Technical and Medical Publishers. stm-assoc.org
STM Association. (2023). Generative AI in Scholarly Communications: Ethical and Practical Guidelines. stm-assoc.org
STM Association. (2026). Toward Responsible Use of Research Content in Generative AI: A Discussion Document. stm-assoc.org
STM Association. (2026). The STM Integrity Hub and the Scholarly Record. stm-assoc.org
Similar Articles









Load more
Frequently Asked Questions
Why is system-level governance important for responsible AI in research?
+System-level governance ensures that generative AI tools operate within established scholarly standards. Without safeguards like metadata integrity, licensing compliance, and clear source attribution, AI outputs can become unreliable or misleading.
How does generative AI impact access to scholarly research?
+Generative AI introduces a complex balance between access and control. While frameworks like STM’s prioritize licensed and publisher-controlled content to protect intellectual property, this can limit access to high-quality research. Without parallel efforts to expand open access, AI systems may reinforce existing paywalls and create a more restricted knowledge ecosystem.
What is the role of researchers in using generative AI responsibly?
+Researchers play a key role in ensuring responsible AI use by verifying outputs, disclosing AI assistance, and maintaining accountability for their work. However, individual diligence cannot replace systemic safeguards. Practice-oriented guidance, such as those developed by Enago, can support ethical AI use.
Can responsible AI use by researchers ensure trustworthy outputs?
+Responsible use by researchers is essential but not sufficient on its own. Trustworthy AI outputs depend on both user behavior and system design. Even careful verification cannot fully address issues like missing citations, unclear source hierarchies, or unverified training data.