Can You Tell if AI Wrote Something? What Researchers Should Look For


For researchers, generative artificial intelligence (GenAI), especially large language models (LLMs), are rapidly transforming how research is written. A recent preprint reports a sharp increase in AI-assisted academic writing following the release of ChatGPT. Adoption has grown rapidly in non–English-speaking countries, where usage rose by approximately 400%, compared with approximately 183% in English-speaking countries.
These trends suggest that AI tools are becoming an integral part of the research writing workflow. As reliance increases, these tools are no longer limited to surface-level editing. They now assist in drafting abstracts, restructuring discussion sections, and improving the overall manuscript preparation process.
This raises an uncomfortable yet essential question for researchers: How can LLMs be used in writing while still preserving genuine authorship, critical thinking, and intellectual integrity?
AI Closely Mirrors Human Writing
Research suggests that AI systems learn to communicate through interaction and feedback, similar to how humans learn. Because LLMs are trained on vast corpora of human language, their outputs closely resemble natural writing styles. This ability to replicate human-like expression, makes it difficult to distinguish between human and machine-produced content at a surface level.
In practice, this is most relevant for authors preparing manuscripts, where recognizing such stylistic clues is increasingly important.
Common Patterns in LLM-Generated Text
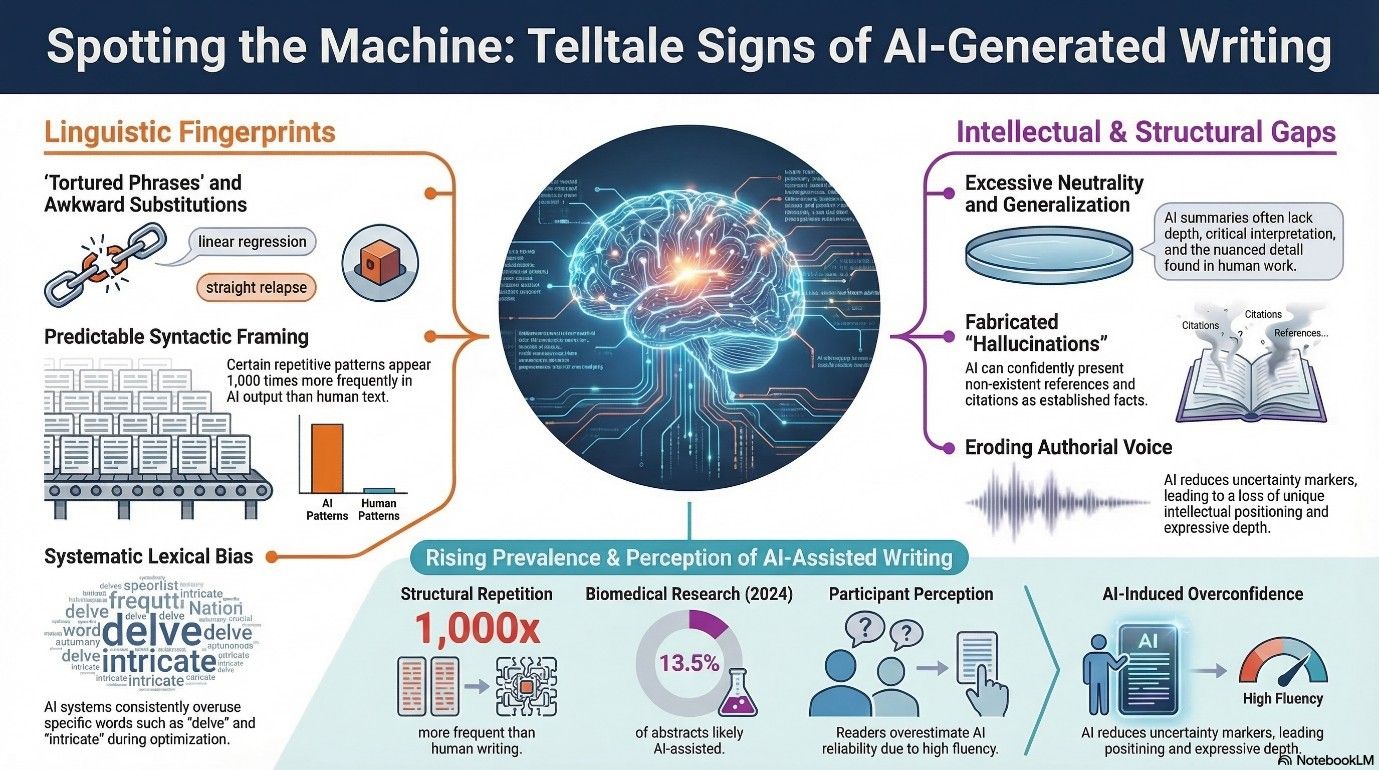
Despite their sophistication, LLMs often produce text with recurring linguistic and stylistic features. Research examining lexical preferences in LLM outputs reveal systematic overuse of certain words like “delve” and “intricate”. Investigation into alignment processes, including reinforcement learning from human feedback (RLHF), show that optimization amplifies these lexical preferences, representing a form of lexical bias that creates measurable differences from typical human writing. These characteristics are not definitive indicators of AI use and may also appear in human-written text.
Awareness of these recurring traits is most useful as a revision strategy, helping authors refine clarity, accuracy, and scholarly voice. LLM outputs should therefore be treated as preliminary draft that requires careful human review and modification.
The following are some common tendencies that authors can watch for in LLM outputs:
1. Tortured phrases
GenAI occasionally substitutes standard terminology with unusual or awkward phrases. These substitutions may sound technically correct but may not reflect the natural writing style of the discipline. A widely discussed case reported by Retraction Watch described a preprint withdrawn after it included phrases like “straight relapse” for “linear regression” and “blunder rate” for “error rate”.
Action: Replace non-standard terms with accepted disciplinary terminology.
2. Excessive neutrality
While AI tools such as ChatGPT can produce clear and readable text, they often lack depth, critical analysis, and contextual interpretation. Empirical research shows that LLM‑generated summaries of scientific papers are significantly more likely to overgeneralize research findings and omit nuanced detail compared to human summaries.
Action: Add critical interpretation and ensure arguments reflect your analysis.
3. Repetitive sentence structures
Another common issue is predictable sentence structures. LLMs frequently rely on predictable syntactic framing, producing paragraphs with similar structural regularities across sections. Recent research shows that some repetitive structures appear over 1,000 times more frequently in LLM output than in human text, indicating systematic overuse of certain phrases and sequences. This trend is also reflected at a large scale in biomedical research. A 2025 biomedical corpus study analyzing more than 15 million abstracts (2010–2024) estimated that at least 13.5% of abstracts published in 2024 show signs of LLM assistance.
Action: Vary sentence structure and phrasing to improve flow and readability.
4. Overgeneralized claims
GenAI produces broad statements that can mask a lack of nuance. Studies indicate that readers frequently overestimate the reliability of such writing due to its fluency, even when inaccuracies are present. In the same study, participants were asked to rate the accuracy of LLM-generated answers. They consistently thought the answers were more reliable than they actually were. This reveals a gap between perceived reliability and actual accuracy.
Action: Verify claims and ensure they are precise, supported, and appropriately qualified.
5. Hallucinations
Outputs from language models may confidently present fabricated or inaccurate information, giving it the appearance of established fact. A 2024 letter published in Intensive Care Medicine included multiple non-existent references, each confidently formatted with convincing citation structure, ultimately leading to the article’s retraction.
Action: Verify all citations, data, and factual statements before submission.
6. Lack of authorial voice
Manuscripts developed with AI support may lack intellectual positioning, methodological reflection, or discipline-specific insight that reflects an author’s research experience. Recent studies show that GenAI is reshaping stance strategies in academic writing by reducing uncertainty markers and increasing more assertive, objective phrasing, signaling a decrease in unique authorial identity and expressive depth.
Action: Revise to reflect your reasoning, interpretation, and domain expertise.
Each of these linguistic and stylistic features discussed above may be subtle, but they can be effectively addressed through careful review. Experimental findings shows that experienced human annotators, particularly those familiar with GenAI tools, can detect AI-generated text by identifying consistent linguistic features, including vocabulary, structure, clarity, and formality. These clues persist even when text is paraphrased or humanized to mimic human writing and appear more natural.
However, this interpretation can be more challenging for many ESL researchers who rely on GenAI tools mainly for language support, such as improving grammar, fluency, and clarity. While this assistance enhances readability, it may also introduce stylistic regularities. It is therefore important to look beyond surface-level fluency and ensure that the manuscript reflects genuine intellectual engagement, domain expertise, and original contribution.
The Role of Human Verification and Modification
The use of LLMs in writing is not inherently problematic. Concerns arise when such tools are used without sufficient verification, modification, or intellectual ownership. Because generated text may contain inaccuracies, overgeneralization, or stylistic distortions that obscure disciplinary meaning, human verification becomes essential to ensure that manuscripts accurately represent the underlying research.
Leading publishers such as Elsevier (Generative AI Policy, 2025) and Nature Portfolio (Editorial Policy on AI) permit the use of AI for drafting but require authors to review, verify, and take full responsibility for all submitted content. In practice, this means assessing factual accuracy and logical coherence, revising outputs to reflect the author’s own data and interpretation, and disclosing AI use in accordance with journal policies.
When used responsibly, AI serves as an assistive tool rather than an autonomous author. Human oversight restores the original scholarly voice, corrects distortions, and incorporates domain-specific expertise that AI cannot provide. Ultimately, the integrity of a manuscript depends not on whether AI is used, but on how responsibly it is used-through careful review and clear authorial ownership.
Similar Articles









Load more
Frequently Asked Questions
Can reviewers tell if AI wrote a research paper?
+Yes. AI-generated text often shows patterns such as repeated sentence structures, unusual phrasing, or overly general statements. Experienced reviewers can identify these stylistic traces during careful evaluation
Can AI-generated text contain factual errors or fabricated information?
+Yes. AI systems can produce incorrect facts or fabricated references, while sounding confident and coherent. This is often called “hallucination,” which is why all information must be carefully reviewed and verified.
What are common signs of AI use in academic writing?
+There are several tell-tale signs of AI-generated text. These patterns include:
- Tortured or unusual technical phrases
- Excessive neutrality and lack of critical interpretation
- Repetitive sentence structures
- Overgeneralized claims
- Hallucinated or fabricated information
- Lack of authorial voice
How can researchers ensure responsible use of AI in writing?
+Human verification is essential. Researchers should critically review AI-generated text, correct inaccuracies, and ensure the manuscript reflects their own analysis and voice. Careful human oversight helps distinguish genuine scholarship from AI text generation.